「淡雪のつもるつもりや砂の上」 (久保田万太郎 1889-1963)
2020年3月18日水曜日
久々のPerl
久しぶりにPerlのプログラムを書いた。20年ぶりとか13年ぶりとか8年ぶりとかの感じ。目的はWHOの "Coronavirus disease (COVID-2019) situation reports" から各国別のConfirmedとDeathsの継時データを取り出すことである。一応形が整ったのであるが,WHOはpdfファイル中の表のデータ構造をコロナウィルスのようにどんどん変化させているので何だかすっきり行かない。結局,一部の古いものについては年度ごとにpdfから取り出したテキストデータ側を手動で調整する必要がある(これらすべてに対応させるほうが面倒なのだ)。
なお,pdfからのテキストファイルの取出にはpdftotextを使った。
(例)$ pdftotext -f 3 -l 6 20200312-sitrep-52-covid-19.pdf 52.txt
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
手元のMacBook Proの Catalina(10.15.3)に附属のperlは2013年バージョン5.18.4(This is perl 5, version 18, subversion 4 (v5.18.4) built for darwin-thread-multi-2level)だった。最新は,5.30.2のようで,Perl6はどうなっているのかと思えば,そうそう楽土になっていた。
なお,pdfからのテキストファイルの取出にはpdftotextを使った。
(例)$ pdftotext -f 3 -l 6 20200312-sitrep-52-covid-19.pdf 52.txt
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
#!/usr/bin/perl
# /usr/local/bin/perl
# 03/17/2020 K. Koshigiri
# extract data from WHO covid-19 reports
# https://www.who.int/emergencies/diseases/
# novel-coronavirus-2019/situation-reports/
# usage:: ./corona.pl Japan ??.txt
$country = shift(@ARGV);
print("$country:\n");
foreach $file (@ARGV) {
open(IN, \$file) || die "\$file: ";
$file =~ /^([0-9]+).txt/;
\$no=\$1;
print($no,',');
while($line = <IN>) {
chomp($line);
if(\$line =~ /\$country\$/) {
$flg='y';
} elsif(\$flg eq 'y' && \$line =~ /([0-9]+)/) {
print("$1,");
} else {
$flg='n';
}
}
print("\n");
}
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -手元のMacBook Proの Catalina(10.15.3)に附属のperlは2013年バージョン5.18.4(This is perl 5, version 18, subversion 4 (v5.18.4) built for darwin-thread-multi-2level)だった。最新は,5.30.2のようで,Perl6はどうなっているのかと思えば,そうそう楽土になっていた。
2020年3月17日火曜日
感染症の数理シミュレーション(9)
感染症の数理シミュレーション(8)からの続き
湖北省(武漢以外)を説明するSIIDR2モデルができたので,これを用いて典型的な2つのイメージを定量化して表現してみたい。以下の計算ではモデルを単純化して特徴を表わすために,感染確率の$\beta$は一定だと仮定する。なお,次のパラメタは固定しておく($\alpha_1=\dfrac{5}{0.80}, \alpha_2=\dfrac{5}{0.20}, \gamma_1=\dfrac{15}{0.96}, \gamma_2=\dfrac{15}{0.04}$)。また,重篤な患者に対して必要な設備(病床)数を,発症して隔離されている感染者数$u_3$の$\dfrac{1}{20}$と想定する。これは,厚生労働省の専門家会議における「新型コロナウイルス感染症の流行シナリオ」に準拠している。
A.短期集団免疫シナリオ
SARS-CoV-2の感染者が完全に免疫を獲得できるのかどうかがよく知らないのだけれど(まれに再感染するのか,単なる変異したウイルスへの感染か),英国のジョンソンやドイツのメルケルが,国民の6〜7割が感染する可能性について言及しているようだ。果たしてそれが可能なのだろうか。SIIDR2モデルで$\beta=0.6,\ \nu=0.01,\ \lambda=10000,\ \tau=0,\ T=180$とする。$\lambda$を十分大きくとったのは$\bar{\beta} \approx \dfrac{8}{15}\beta$(一定)になるようにするためだ。

グラフの基点は新規感染者累計が人口の1ppmに達した時点であり,感染者が増大している多くの国では条件を満足している。日本に当てはめると,ピークは3〜4ヶ月後(5〜6月)$u_1$:未感染数,$u_2$:軽症感染数(含む未発症),$u_3$:重症感染数(ピーク時400万人),$u_4$:死亡数(終期は60万人),$u_5$:免疫獲得回復数(終期は7000万人),$u_6$:重症感染数累計(終期は1400万人)である。したがってピーク時の重篤用必要設備(病床)数は20万床となり,完全に国内のキャパシティを越えてしまうものと思われる。当然オリンピックは不可能だ。
B.ピークシフトシナリオ
医療崩壊の本質は,PCR検査の数の問題でも,病床数の問題でもなく,重篤患者に対応するための設備と医者の数の問題であるといわれている。日本の厚生労働省がNHKを通じて広めている図も,ピークを低くしてその頂上の位置を先送りにする必要があるというものだった。SIIDR2モデルで$\beta=0.42,\ \nu=0.01,\ \lambda=10000,\ \tau=0,\ T=750$としたものが次の図である。図1とスケールのオーダーやファクターが違うことに注意しよう。

感染数のピークは10〜16ヶ月後,$u_2$:軽症感染数(含む未発症)(ピーク時50万人),$u_3$:重症感染数(ピーク時30万人),$u_4$:死亡数(終期は10万人),$u_6$:重症感染数累計(終期は300万人)である。したがってピーク時の重篤用必要設備(病床)数は1.5万床となり,かろうじて対応できるのかもしれないがよくわからない。大きな問題は2年にわたる長期の対応が必要なことである。ピークシフトを考える場合は,感染率$\beta$の抑制策との合わせ技が必須だ。
[1]ピークカット戦略(集団免疫戦略)地獄への道は善意で舗装されている(Sato Hiroshi)
湖北省(武漢以外)を説明するSIIDR2モデルができたので,これを用いて典型的な2つのイメージを定量化して表現してみたい。以下の計算ではモデルを単純化して特徴を表わすために,感染確率の$\beta$は一定だと仮定する。なお,次のパラメタは固定しておく($\alpha_1=\dfrac{5}{0.80}, \alpha_2=\dfrac{5}{0.20}, \gamma_1=\dfrac{15}{0.96}, \gamma_2=\dfrac{15}{0.04}$)。また,重篤な患者に対して必要な設備(病床)数を,発症して隔離されている感染者数$u_3$の$\dfrac{1}{20}$と想定する。これは,厚生労働省の専門家会議における「新型コロナウイルス感染症の流行シナリオ」に準拠している。
A.短期集団免疫シナリオ
SARS-CoV-2の感染者が完全に免疫を獲得できるのかどうかがよく知らないのだけれど(まれに再感染するのか,単なる変異したウイルスへの感染か),英国のジョンソンやドイツのメルケルが,国民の6〜7割が感染する可能性について言及しているようだ。果たしてそれが可能なのだろうか。SIIDR2モデルで$\beta=0.6,\ \nu=0.01,\ \lambda=10000,\ \tau=0,\ T=180$とする。$\lambda$を十分大きくとったのは$\bar{\beta} \approx \dfrac{8}{15}\beta$(一定)になるようにするためだ。

図1 短期集団免疫シナリオ(1万人当り)
グラフの基点は新規感染者累計が人口の1ppmに達した時点であり,感染者が増大している多くの国では条件を満足している。日本に当てはめると,ピークは3〜4ヶ月後(5〜6月)$u_1$:未感染数,$u_2$:軽症感染数(含む未発症),$u_3$:重症感染数(ピーク時400万人),$u_4$:死亡数(終期は60万人),$u_5$:免疫獲得回復数(終期は7000万人),$u_6$:重症感染数累計(終期は1400万人)である。したがってピーク時の重篤用必要設備(病床)数は20万床となり,完全に国内のキャパシティを越えてしまうものと思われる。当然オリンピックは不可能だ。
B.ピークシフトシナリオ
医療崩壊の本質は,PCR検査の数の問題でも,病床数の問題でもなく,重篤患者に対応するための設備と医者の数の問題であるといわれている。日本の厚生労働省がNHKを通じて広めている図も,ピークを低くしてその頂上の位置を先送りにする必要があるというものだった。SIIDR2モデルで$\beta=0.42,\ \nu=0.01,\ \lambda=10000,\ \tau=0,\ T=750$としたものが次の図である。図1とスケールのオーダーやファクターが違うことに注意しよう。

図2 ピークシフトシナリオ(1万人当り)
[1]ピークカット戦略(集団免疫戦略)地獄への道は善意で舗装されている(Sato Hiroshi)
2020年3月16日月曜日
日本の歴史
4月12日まで期間限定無料提供されている,小学館版学習漫画少年少女日本の歴史全24巻(22巻+付録2巻)をざっと読み終えた。第22巻の平成編はそれまでのものとトーンが違っており,全く面白くなかった。それ以外はとてもよかった。権力の移行過程に加えて,文化的なトピックスや民衆の動きなどが適当なバランスで記述されており,1巻の中を3〜4つのテーマに分けながら進めていくスタイルはとても理解しやすい。南京大虐殺や三光作戦や慰安婦などもちゃんと触れており,夏目漱石のところには米山保三郎も登場していた。第21巻あたりでは著作権の関係か背景がグレーに処理されていて新聞などの紙面?が再現されていないものがあるのがちょっと残念だった。
歴史といえば,大学時代に井上清(1915-2001)の岩波新書「日本の歴史(上・中・下)」を読んでいたことを思い出した。これもなかなか貴重な読書体験だった。史実の正確性や著者のマルクス主義的歴史観に対してはいろいろ批判はあるようだが,当時はとても新鮮に感じられた。
歴史といえば,小学校高学年のころか,父親が平泉澄(1895-1984)の「少年日本史」をどこからかもらってきて,これを読めと渡されたことがある。パラパラと見たところ直観的にこれはインチキだとすぐわかったのでほとんど読まなかった。父にこれ(皇国史観)はおかしいというと,叱られたような気がする。その頃は家にあった6巻ものの漫画ではない学研かどこかの日本の歴史を読んでいてこちらの方はまともでおもしろかった。
歴史といえば,大学時代に井上清(1915-2001)の岩波新書「日本の歴史(上・中・下)」を読んでいたことを思い出した。これもなかなか貴重な読書体験だった。史実の正確性や著者のマルクス主義的歴史観に対してはいろいろ批判はあるようだが,当時はとても新鮮に感じられた。
歴史といえば,小学校高学年のころか,父親が平泉澄(1895-1984)の「少年日本史」をどこからかもらってきて,これを読めと渡されたことがある。パラパラと見たところ直観的にこれはインチキだとすぐわかったのでほとんど読まなかった。父にこれ(皇国史観)はおかしいというと,叱られたような気がする。その頃は家にあった6巻ものの漫画ではない学研かどこかの日本の歴史を読んでいてこちらの方はまともでおもしろかった。
2020年3月15日日曜日
感染症の数理シミュレーション(8)
感染症の数理シミュレーション(7)からの続き
中間まとめ
いろいろと書き散らしてきたので,ここまでに得られた結果を整理してみる。
感染症の数理シミュレーション(3)において,感染対策時間因子を修正した図1のSIIDR2モデルで,湖北省(武漢以外)の新規感染者数累計と死亡数累計を説明できるパラメタセットを得ることができた。

\begin{equation}
\begin{aligned}
S: \dfrac{du_1}{dt} &= -\dfrac{\beta(t)}{n} u_1 u_2\\
I_1: \dfrac{du_2}{dt} &= \dfrac{\beta(t)}{n} u_1 u_2 -\dfrac{u_2}{\alpha_1} -\dfrac{u_2}{\alpha_2}\\
I_2: \dfrac{du_3}{dt} &= \dfrac{u_2}{\alpha_2} - \dfrac{u_3}{\gamma_1} -\dfrac{u_3}{\gamma_2}\\
D: \dfrac{du_4}{dt} &= \dfrac{u_3}{\gamma_2}\\
R: \dfrac{du_5}{dt} &= \dfrac{u_2}{\alpha_1} + \dfrac{u_3}{\gamma_1}\\
I_a: \dfrac{du_6}{dt} &= \dfrac{u_2}{\alpha_2}\\
\beta(t)&= \dfrac{\beta}{15}\{8+7 \tanh(-\frac{t-\tau}{\lambda})
\end{aligned}
\end{equation}
湖北省(武漢以外)のデータを再現するパラメタセットは以下のとおりであり,これを用いたシミュレーション結果は図2のように与えられる。
$\alpha_1=5/0.80, \alpha_2=5/0.20=25$, $\beta=0.915$, $\gamma_1=15/0.96, \gamma_2=15/0.04=375$, $\lambda=\tau=7, \nu=0.025$,$u_2$が軽症感染者数(発症無),$u_3$が重症感染者数(発症有),$\dfrac{u_2}{\alpha_2}$が新規重症感染者数$f(t)$,$\dfrac{u_3}{\gamma_2}$が新規死亡数$h(t)$,$u_4$が死亡数累計$i(t)=\int h(t) dt$,$u_6$が新規重症感染者累計$g(t)=\int f(t) dt$,である。WHOで報告されているデータ[1]では,感染者累計(Confirmed)が$g(t)$,死亡数累計(Deaths)が$i(t)$に対応している。

半分パラメタフィッティングなので,$\nu,\tau,\lambda$を調整して勝手に象の鼻を描いている感は否めないのが微妙なところである。
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
using DifferentialEquations
using ParameterizedFunctions
using Plots; gr()
sky = @ode_def SIIDR2_model begin
du0 = 1 # u0:time
du1 = -β/15*(8+7*tanh(-(u0-τ)/λ))*u1*u2/n # u1:Noimmunity(Susceptible)
du2 = β/15*(8+7*tanh(-(u0-τ)/λ))*u1*u2/n -u2/α1 -u2/α2 # u2:Mild(Infected-a)
du3 = u2/α2 -u3/γ1 -u3/γ2 # u3:Serious(Infected-b)
du4 = u3/γ2 # u4:Dead
du5 = u2/α1 +u3/γ1 # u5:Recovered
du6 = u2/α2 # u6:Accumulated Infected-b
end n α1 α2 β γ1 γ2 λ τ
function epidm(β,ν,λ,τ,T)
n=10000.0 #total number of population
α1=5.0/0.80 #latent to recovery (days/%)
α2=5.0/0.20 #latent to onset (days/%)
#β=0.45 #infection rate (/day・person)
γ1=15.0/0.96 #onset to recovery (days/%)
γ2=15.0/0.04 #onset to death (days/%)
u0 = [0.0,n-11ν,4ν,2ν,0.0,5ν,ν] #initial values
p = (n,α1,α2,β,γ1,γ2,λ,τ) #parameters
tspan = (0.0,T) #time span in days
prob = ODEProblem(sky,u0,tspan,p)
sol = solve(prob)
return sol
end
β=0.915 #infection rate
ν=0.025 #inital value of accumulated infected-b
λ=7 #pandemic supression range (days)
τ=7 #pandemic supression start (day)
T=40 #period of simulation
xc=[0,3,6,9,12,15,18,21,24,27,30,33,36,39,42,45,48]
yc=[0.003,0.03,0.23,0.67,1.27,2.00,2.52,2.88,
3.44,3.58,3.71,3.69,3.71,3.71,3.71,3.71,3.71]
zc=[0.0,0.0,0.0,0.01,0.02,0.03,0.04,0.05,
0.07,0.09,0.10,0.11,0.11,0.12,0.12,0.13,0.13]
# kohoku-bukan model
# β=0.915,ν=0.025,λ=7,τ=7,α2=5.0/0.20,γ2=15.0/0.04
@time so=epidm(β,ν,λ,τ,T)
#plot(so,vars=(0,2))
plot(so,vars=(0,3))
plot!(so,vars=(0,4))
plot!(so,vars=(0,5))
plot!(so,vars=(0,6))
plot!(so,vars=(0,7))
plot!(xc,yc,st=:scatter)
plot!(xc,zc,st=:scatter)
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
[1]Coronavirus disease (COVID-2019) situation reports
[2]新型環状病毒肺炎疫情動態(tencentニュースサイト)
[3]新型コロナウイルス感染症対策専門家会議(第5回)(3月2日)
[4]特設サイト:新型コロナウイルス(NHK)
[5]新型コロナウイルス感染速報(Su Wei)
[6]Coronavirus Disease (COVID-19) – Statistics and Research(Our World in DATA)
[7]Databrew's COVID-19 data explorer(Databrew)
[8]COVID-19情報共有(佐藤彰洋)
[9]時間遅れを考慮した確率 SIR モデルの安定性解析(石川昌明)
[10]分布的時間遅れをもつ確率感染症モデルの安定性解析(石川昌明)
P. S. [6]のように,プロがシミュレーションをすると遅延SIRモデルみたいなことになるのか。感染率にステップ関数を導入しているので鋭い構造が出現しているようだ。遅延確率SIRモデルになるとちょっとついていけません(3/17/2020)。
感染症の数理シミュレーション(9)に続く
中間まとめ
いろいろと書き散らしてきたので,ここまでに得られた結果を整理してみる。
感染症の数理シミュレーション(3)において,感染対策時間因子を修正した図1のSIIDR2モデルで,湖北省(武漢以外)の新規感染者数累計と死亡数累計を説明できるパラメタセットを得ることができた。

図1 SIIDR2モデルの概念図,$n=u_1+u_2+u_3+u_4+u_5$, $p+q=1$
\begin{equation}
\begin{aligned}
S: \dfrac{du_1}{dt} &= -\dfrac{\beta(t)}{n} u_1 u_2\\
I_1: \dfrac{du_2}{dt} &= \dfrac{\beta(t)}{n} u_1 u_2 -\dfrac{u_2}{\alpha_1} -\dfrac{u_2}{\alpha_2}\\
I_2: \dfrac{du_3}{dt} &= \dfrac{u_2}{\alpha_2} - \dfrac{u_3}{\gamma_1} -\dfrac{u_3}{\gamma_2}\\
D: \dfrac{du_4}{dt} &= \dfrac{u_3}{\gamma_2}\\
R: \dfrac{du_5}{dt} &= \dfrac{u_2}{\alpha_1} + \dfrac{u_3}{\gamma_1}\\
I_a: \dfrac{du_6}{dt} &= \dfrac{u_2}{\alpha_2}\\
\beta(t)&= \dfrac{\beta}{15}\{8+7 \tanh(-\frac{t-\tau}{\lambda})
\end{aligned}
\end{equation}
湖北省(武漢以外)のデータを再現するパラメタセットは以下のとおりであり,これを用いたシミュレーション結果は図2のように与えられる。
$\alpha_1=5/0.80, \alpha_2=5/0.20=25$, $\beta=0.915$, $\gamma_1=15/0.96, \gamma_2=15/0.04=375$, $\lambda=\tau=7, \nu=0.025$,$u_2$が軽症感染者数(発症無),$u_3$が重症感染者数(発症有),$\dfrac{u_2}{\alpha_2}$が新規重症感染者数$f(t)$,$\dfrac{u_3}{\gamma_2}$が新規死亡数$h(t)$,$u_4$が死亡数累計$i(t)=\int h(t) dt$,$u_6$が新規重症感染者累計$g(t)=\int f(t) dt$,である。WHOで報告されているデータ[1]では,感染者累計(Confirmed)が$g(t)$,死亡数累計(Deaths)が$i(t)$に対応している。

図2 湖北省(武漢以外)のSIIDR2モデルによるシミュレーション
(○はConfirmedとDeathsの観測値,WHOとtencentニュースサイトのデータ)
半分パラメタフィッティングなので,$\nu,\tau,\lambda$を調整して勝手に象の鼻を描いている感は否めないのが微妙なところである。
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
using DifferentialEquations
using ParameterizedFunctions
using Plots; gr()
sky = @ode_def SIIDR2_model begin
du0 = 1 # u0:time
du1 = -β/15*(8+7*tanh(-(u0-τ)/λ))*u1*u2/n # u1:Noimmunity(Susceptible)
du2 = β/15*(8+7*tanh(-(u0-τ)/λ))*u1*u2/n -u2/α1 -u2/α2 # u2:Mild(Infected-a)
du3 = u2/α2 -u3/γ1 -u3/γ2 # u3:Serious(Infected-b)
du4 = u3/γ2 # u4:Dead
du5 = u2/α1 +u3/γ1 # u5:Recovered
du6 = u2/α2 # u6:Accumulated Infected-b
end n α1 α2 β γ1 γ2 λ τ
function epidm(β,ν,λ,τ,T)
n=10000.0 #total number of population
α1=5.0/0.80 #latent to recovery (days/%)
α2=5.0/0.20 #latent to onset (days/%)
#β=0.45 #infection rate (/day・person)
γ1=15.0/0.96 #onset to recovery (days/%)
γ2=15.0/0.04 #onset to death (days/%)
u0 = [0.0,n-11ν,4ν,2ν,0.0,5ν,ν] #initial values
p = (n,α1,α2,β,γ1,γ2,λ,τ) #parameters
tspan = (0.0,T) #time span in days
prob = ODEProblem(sky,u0,tspan,p)
sol = solve(prob)
return sol
end
β=0.915 #infection rate
ν=0.025 #inital value of accumulated infected-b
λ=7 #pandemic supression range (days)
τ=7 #pandemic supression start (day)
T=40 #period of simulation
xc=[0,3,6,9,12,15,18,21,24,27,30,33,36,39,42,45,48]
yc=[0.003,0.03,0.23,0.67,1.27,2.00,2.52,2.88,
3.44,3.58,3.71,3.69,3.71,3.71,3.71,3.71,3.71]
zc=[0.0,0.0,0.0,0.01,0.02,0.03,0.04,0.05,
0.07,0.09,0.10,0.11,0.11,0.12,0.12,0.13,0.13]
# kohoku-bukan model
# β=0.915,ν=0.025,λ=7,τ=7,α2=5.0/0.20,γ2=15.0/0.04
@time so=epidm(β,ν,λ,τ,T)
#plot(so,vars=(0,2))
plot(so,vars=(0,3))
plot!(so,vars=(0,4))
plot!(so,vars=(0,5))
plot!(so,vars=(0,6))
plot!(so,vars=(0,7))
plot!(xc,yc,st=:scatter)
plot!(xc,zc,st=:scatter)
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
[2]新型環状病毒肺炎疫情動態(tencentニュースサイト)
[3]新型コロナウイルス感染症対策専門家会議(第5回)(3月2日)
[4]特設サイト:新型コロナウイルス(NHK)
[5]新型コロナウイルス感染速報(Su Wei)
[6]Coronavirus Disease (COVID-19) – Statistics and Research(Our World in DATA)
[7]Databrew's COVID-19 data explorer(Databrew)
[8]COVID-19情報共有(佐藤彰洋)
[9]時間遅れを考慮した確率 SIR モデルの安定性解析(石川昌明)
[10]分布的時間遅れをもつ確率感染症モデルの安定性解析(石川昌明)
P. S. [6]のように,プロがシミュレーションをすると遅延SIRモデルみたいなことになるのか。感染率にステップ関数を導入しているので鋭い構造が出現しているようだ。遅延確率SIRモデルになるとちょっとついていけません(3/17/2020)。
感染症の数理シミュレーション(9)に続く
2020年3月14日土曜日
感染症の数理シミュレーション(7)
感染症の数理シミュレーション(6)からの続き
動機
岩田健太郎さんが,新型コロナウイルス感染症対策専門家会議(第5回)の参考資料「新型コロナウイルス感染症の流行シナリオ(2 月 29 日時点)」を紹介していた。そこでは,基本再生産数$R_o=1.7$として,発病間隔を4日としていた。$\beta=1.7/4=0.42$であり,これらはこれまでの想定と矛盾しない。ところが入院期間や重症期間を15日と設定しており,これまでの$\gamma=5$という想定とは異なっている。そこで,前回の考察を見直したところ,導出根拠が不正確な部分があったので再検討する。
方針
中国の湖北省(武漢以外,人口4800万人)の感染データは感染者数が最も大きくほぼ収束しているデータである。新規確定感染者数 , 累計 $f(t) , g(t)=\int f(t) dt$と新規死亡数 , 累計 $h(t) , i(t)=\int h(t) dt$ が観測値として得られており,武漢のような特異性(突出した致死率)をもたない。そこで,これのデータを簡単な関数で近似して,SIIDR2モデルにあてはめることにより,モデルのパラメタである$\beta, \gamma_1, \gamma_2$を観測値から推定しようというものである。なお,前回の議論から$\alpha_1 = \dfrac{5}{0.8} = 6.25,\ \alpha_2 = \dfrac{5}{0.2} = 25,\ \dfrac{\alpha_2}{\alpha_1}=4$は前提とする。
SIIDR2モデル式($u_1 \approx n$, $\beta$=一定とした場合)
\begin{equation}
\begin{aligned}
u_1 &= n - \int \beta u_2 dt = n - 25 \beta g\\
u_2 &= 25 \beta g -5 g\\
u_3 &= \gamma_2 h\\
u_4 &= i\\
u_5 &= 4 g + \dfrac{\gamma_2}{\gamma_1} i \\
u_6 &= g
\end{aligned}
\end{equation}
これを$u_1+u_2+u_3+u_4+u_5=n$に代入して次式が得られる。
\begin{equation}
g(t) = \gamma_2 h(t) + (1+ \dfrac{\gamma_2}{\gamma_1}) i(t)
\end{equation}
この左辺と右辺がほぼ等しくなる$\gamma_1, \gamma_2$を探す。
観測値の近似式
湖北省(武漢以外)の観測値(1万人当りに換算)を再現するものとして前回と同様に次の近似関数を採用する。ただし,$h(t)$は前回から修正した。
\begin{equation}
\begin{aligned}
f(t) = t^4 \exp(-t/3) / 1600\\
g(t) = \int f(t) dt ; g(0)=0\\
h(t) = 1.4 t \exp(-(t - 20)^2/12^2) /4800\\
i(t) = \int h(t) dt ; i(0)=0
\end{aligned}
\end{equation}
$h(t), i(t)$を24倍($\gamma_2/\gamma_1$)したグラフを$f(t), g(t)$と重ねたものを図1に示す。

最適値の検討
$r(t) = \{ \gamma_2 h(t) + (1+ \dfrac{\gamma_2}{\gamma_1}) i(t) \}/g(t)$を$t=10$から$t=30$の範囲でプロットして$r(t)$の値がほぼフラットであり平均して1前後になる$\gamma_1, \gamma_2$を探す。上記専門家会議の議論を踏まえて,$\frac{1}{\gamma}=\frac{1}{\gamma_1}+\frac{1}{\gamma_2}=\frac{1}{15}$とする。なお,これまでの$\gamma=5$を用いると$r(t)$が0.6あたりまで減ってしまう。結局,
\begin{equation}
\gamma_1 = \dfrac{15}{0.96}, \quad \gamma_2 = \dfrac{15}{0.04}
\end{equation}
このとき,$r(t)$の平均値として$\dfrac{1}{20} \int_{10}^{30} r(t) dt = 1.05$が得られるので,条件を満足している。

まとめ
湖北省(武漢以外)の1/20/2020から2/29/2020のデータを再現するSIIDR2モデルのパラメタとしては,次のセットが推奨される。
\begin{equation}
\alpha_1 = \dfrac{5}{0.8} ,\quad \alpha_2 = \dfrac{5}{0.2} ,\quad \bar{\beta}=0.4 \sim 0.5 ,\quad \gamma_1 = \dfrac{15}{0.96} ,\quad \gamma_2 = \dfrac{15}{0.04}
\end{equation}
付録 初期値$\nu$の取り扱い
これまでは,$u_2$の初期値を$\nu$としてきた。ところで,各国の感染者比(1)と各国の感染者比(2)から新規感染者数累計が人口の1ppmを越えた$t_0$を始点とするモデル化が必要があることがわかった。そこで,$t_0$における初期条件を再度検討する。はじめに$h(t_0)=i(t_0)=0$と近似した上で,上記関係式より,$u_2(t_0)=25 f(t_0), u_5(t_0)=4 g(t_0) , u_6(t_0)=g(t_0)$となる。ここで,$g(t_0)=\nu$と再定義する。$\nu$=1ppmが始点になる。
ところで,$f(t)=k t^m$と仮定すると
\begin{equation}
\begin{aligned}
g(t) &=\int f(t) dt = \dfrac{k t^{m+1}}{m+1}=\dfrac{t f(t)}{m+1}\\
\therefore f(t_0) &= \dfrac{m+1}{t_0} g(t_0) = \dfrac{m+1}{t_0} \nu
\end{aligned}
\end{equation}
したがって,$u_2(t_0)=\dfrac{25}{t_0}(m+1) \nu \approx 4\nu$となる。ただし,日本の1ppmに至るまでの観測値から,$t_0 \approx 25, m \approx 3$とおいた。
追加(3/17/2020)
次に,$u_3(t_0)$について考える。これは次の微分方程式を満たす。
\begin{equation}
\dfrac{du_3}{dt}=f -\dfrac{u_3}{\gamma}
\end{equation}
ここで,$u_3(t)=k t$と仮定して代入すると,$k = f -\dfrac{k t}{\gamma}$である。そこで,
$k=\dfrac{f(t_0)}{1+t_0/\gamma}$となる。上の結果から,$u_2(t_0)=25 f(t_0)$,したがって,次式が成り立つ。
\begin{equation}
u_3(t_0)= \dfrac{f(t_0)}{1+t_0/\gamma} t_0 = u_2(t_0) \dfrac{25}{t_0 (1+t_0/\gamma)}
\approx u_2(t_0) \dfrac{1}{(1+t_0/\gamma)} \sim \dfrac{1}{2} u_2(t_0) = 2\nu
\end{equation}
さらに,$h(t_0)=i(t_0)=0$という条件をゆるめてみる。$u_3=\dfrac{u_2}{2}=375 h$より,$\int u_2 dt = 750 \int h dt = 750 i$,一方,$g = \int f dt = \dfrac{1}{25} \int u_2 dt$。したがって,$i = \dfrac{1}{30} g$となる。これから,$u_5(t_0)=4 g(t_0) + \dfrac{24}{30} g(t_0) \approx 5 \nu$となる。なお,$u_4(t_0)=i(t_0)= \dfrac{g(t_0)}{30} = \dfrac{\nu}{30} $なので,これはゼロのままとする。
この結果$u_1(t_0)=n-u_2(t_0)-u_3(t_0)-u_4(t_0)-u_5(t_0)=n-4\nu-2\nu-5\nu=n-11\nu$となり,新規感染者数累計が1ppmになる時点には,約11ppmの軽症感染者・重症感染者・死亡者・免疫獲得回復者が存在することになる。
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
まとめると,$\nu$=1ppm時点の初期値を次のように設定する。
\begin{equation}
u_1(t_0)=n-11\nu, \quad u_2(t_0)=4\nu, \quad u_3(t_0)=2\nu, \quad u_4(t_0)=0, \quad u_5(t_0)=5\nu, \quad u_6(t_0)=\nu
\end{equation}
感染症の数理シミュレーション(8)に続く
動機
岩田健太郎さんが,新型コロナウイルス感染症対策専門家会議(第5回)の参考資料「新型コロナウイルス感染症の流行シナリオ(2 月 29 日時点)」を紹介していた。そこでは,基本再生産数$R_o=1.7$として,発病間隔を4日としていた。$\beta=1.7/4=0.42$であり,これらはこれまでの想定と矛盾しない。ところが入院期間や重症期間を15日と設定しており,これまでの$\gamma=5$という想定とは異なっている。そこで,前回の考察を見直したところ,導出根拠が不正確な部分があったので再検討する。
方針
中国の湖北省(武漢以外,人口4800万人)の感染データは感染者数が最も大きくほぼ収束しているデータである。新規確定感染者数 , 累計 $f(t) , g(t)=\int f(t) dt$と新規死亡数 , 累計 $h(t) , i(t)=\int h(t) dt$ が観測値として得られており,武漢のような特異性(突出した致死率)をもたない。そこで,これのデータを簡単な関数で近似して,SIIDR2モデルにあてはめることにより,モデルのパラメタである$\beta, \gamma_1, \gamma_2$を観測値から推定しようというものである。なお,前回の議論から$\alpha_1 = \dfrac{5}{0.8} = 6.25,\ \alpha_2 = \dfrac{5}{0.2} = 25,\ \dfrac{\alpha_2}{\alpha_1}=4$は前提とする。
SIIDR2モデル式($u_1 \approx n$, $\beta$=一定とした場合)
\begin{equation}
\begin{aligned}
u_1 &= n - \int \beta u_2 dt = n - 25 \beta g\\
u_2 &= 25 \beta g -5 g\\
u_3 &= \gamma_2 h\\
u_4 &= i\\
u_5 &= 4 g + \dfrac{\gamma_2}{\gamma_1} i \\
u_6 &= g
\end{aligned}
\end{equation}
これを$u_1+u_2+u_3+u_4+u_5=n$に代入して次式が得られる。
\begin{equation}
g(t) = \gamma_2 h(t) + (1+ \dfrac{\gamma_2}{\gamma_1}) i(t)
\end{equation}
この左辺と右辺がほぼ等しくなる$\gamma_1, \gamma_2$を探す。
観測値の近似式
湖北省(武漢以外)の観測値(1万人当りに換算)を再現するものとして前回と同様に次の近似関数を採用する。ただし,$h(t)$は前回から修正した。
\begin{equation}
\begin{aligned}
f(t) = t^4 \exp(-t/3) / 1600\\
g(t) = \int f(t) dt ; g(0)=0\\
h(t) = 1.4 t \exp(-(t - 20)^2/12^2) /4800\\
i(t) = \int h(t) dt ; i(0)=0
\end{aligned}
\end{equation}
$h(t), i(t)$を24倍($\gamma_2/\gamma_1$)したグラフを$f(t), g(t)$と重ねたものを図1に示す。

図1 ピークと変曲点の時点が$t=12$の$f(t),\ g(t)$及び$t=24$の$h(t),\ i(t)$
最適値の検討
$r(t) = \{ \gamma_2 h(t) + (1+ \dfrac{\gamma_2}{\gamma_1}) i(t) \}/g(t)$を$t=10$から$t=30$の範囲でプロットして$r(t)$の値がほぼフラットであり平均して1前後になる$\gamma_1, \gamma_2$を探す。上記専門家会議の議論を踏まえて,$\frac{1}{\gamma}=\frac{1}{\gamma_1}+\frac{1}{\gamma_2}=\frac{1}{15}$とする。なお,これまでの$\gamma=5$を用いると$r(t)$が0.6あたりまで減ってしまう。結局,
\begin{equation}
\gamma_1 = \dfrac{15}{0.96}, \quad \gamma_2 = \dfrac{15}{0.04}
\end{equation}
このとき,$r(t)$の平均値として$\dfrac{1}{20} \int_{10}^{30} r(t) dt = 1.05$が得られるので,条件を満足している。

図2 $t=10$から$t=30$における$r(t)$の振る舞い
また前回の,$\beta(t)=\dfrac{df}{dt} / f + \dfrac{1}{\alpha}$についての議論はそのままであり変更されていないことに注意する。SIIDR2モデルを採用すれば,武漢(湖北以外)では$\beta(t)$を急速に小さくしたことが考えられる。なお,基本再生産率$R_o$と$\alpha$の値から$\beta$を一定とした場合の平均値は$\bar{\beta}=0.4 \sim 0.5$である。
また前回の,$\beta(t)=\dfrac{df}{dt} / f + \dfrac{1}{\alpha}$についての議論はそのままであり変更されていないことに注意する。SIIDR2モデルを採用すれば,武漢(湖北以外)では$\beta(t)$を急速に小さくしたことが考えられる。なお,基本再生産率$R_o$と$\alpha$の値から$\beta$を一定とした場合の平均値は$\bar{\beta}=0.4 \sim 0.5$である。
まとめ
湖北省(武漢以外)の1/20/2020から2/29/2020のデータを再現するSIIDR2モデルのパラメタとしては,次のセットが推奨される。
\begin{equation}
\alpha_1 = \dfrac{5}{0.8} ,\quad \alpha_2 = \dfrac{5}{0.2} ,\quad \bar{\beta}=0.4 \sim 0.5 ,\quad \gamma_1 = \dfrac{15}{0.96} ,\quad \gamma_2 = \dfrac{15}{0.04}
\end{equation}
付録 初期値$\nu$の取り扱い
これまでは,$u_2$の初期値を$\nu$としてきた。ところで,各国の感染者比(1)と各国の感染者比(2)から新規感染者数累計が人口の1ppmを越えた$t_0$を始点とするモデル化が必要があることがわかった。そこで,$t_0$における初期条件を再度検討する。はじめに$h(t_0)=i(t_0)=0$と近似した上で,上記関係式より,$u_2(t_0)=25 f(t_0), u_5(t_0)=4 g(t_0) , u_6(t_0)=g(t_0)$となる。ここで,$g(t_0)=\nu$と再定義する。$\nu$=1ppmが始点になる。
ところで,$f(t)=k t^m$と仮定すると
\begin{equation}
\begin{aligned}
g(t) &=\int f(t) dt = \dfrac{k t^{m+1}}{m+1}=\dfrac{t f(t)}{m+1}\\
\therefore f(t_0) &= \dfrac{m+1}{t_0} g(t_0) = \dfrac{m+1}{t_0} \nu
\end{aligned}
\end{equation}
したがって,$u_2(t_0)=\dfrac{25}{t_0}(m+1) \nu \approx 4\nu$となる。ただし,日本の1ppmに至るまでの観測値から,$t_0 \approx 25, m \approx 3$とおいた。
追加(3/17/2020)
次に,$u_3(t_0)$について考える。これは次の微分方程式を満たす。
\begin{equation}
\dfrac{du_3}{dt}=f -\dfrac{u_3}{\gamma}
\end{equation}
ここで,$u_3(t)=k t$と仮定して代入すると,$k = f -\dfrac{k t}{\gamma}$である。そこで,
$k=\dfrac{f(t_0)}{1+t_0/\gamma}$となる。上の結果から,$u_2(t_0)=25 f(t_0)$,したがって,次式が成り立つ。
\begin{equation}
u_3(t_0)= \dfrac{f(t_0)}{1+t_0/\gamma} t_0 = u_2(t_0) \dfrac{25}{t_0 (1+t_0/\gamma)}
\approx u_2(t_0) \dfrac{1}{(1+t_0/\gamma)} \sim \dfrac{1}{2} u_2(t_0) = 2\nu
\end{equation}
さらに,$h(t_0)=i(t_0)=0$という条件をゆるめてみる。$u_3=\dfrac{u_2}{2}=375 h$より,$\int u_2 dt = 750 \int h dt = 750 i$,一方,$g = \int f dt = \dfrac{1}{25} \int u_2 dt$。したがって,$i = \dfrac{1}{30} g$となる。これから,$u_5(t_0)=4 g(t_0) + \dfrac{24}{30} g(t_0) \approx 5 \nu$となる。なお,$u_4(t_0)=i(t_0)= \dfrac{g(t_0)}{30} = \dfrac{\nu}{30} $なので,これはゼロのままとする。
この結果$u_1(t_0)=n-u_2(t_0)-u_3(t_0)-u_4(t_0)-u_5(t_0)=n-4\nu-2\nu-5\nu=n-11\nu$となり,新規感染者数累計が1ppmになる時点には,約11ppmの軽症感染者・重症感染者・死亡者・免疫獲得回復者が存在することになる。
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
まとめると,$\nu$=1ppm時点の初期値を次のように設定する。
\begin{equation}
u_1(t_0)=n-11\nu, \quad u_2(t_0)=4\nu, \quad u_3(t_0)=2\nu, \quad u_4(t_0)=0, \quad u_5(t_0)=5\nu, \quad u_6(t_0)=\nu
\end{equation}
感染症の数理シミュレーション(8)に続く
2020年3月13日金曜日
小学館版学習漫画少年少女日本の歴史
新型コロナウイル感染症のため全国の学校が休校になり,さまざまな対応措置が講じられている。そのひとつが子ども向け学習・娯楽コンテンツの期間限定無料提供である。例えば,小学館版学習漫画少年少女日本の歴史全24巻(22巻+付録2巻)が2020年3月11日から4月12日まで無料公開されている。
さっそく読み始めました。いやーおもしろくてためになる。高校のときは理数科で世界史と日本史は片方のみが選択だった。それならば世界史でしょうということで,受験に不利かもしれない世界史を選択したため,日本史は小学校の知識でとどまっている。中学校社会の歴史は,途中で交代もあったかもしれないなんだかもうひとつの先生で(地理の米山先生は若くて授業に集中できたのに),試験の成績も全く振るわなかったのだ。
小学校で歴史を学ぶのは6年生である。5年生が地理。その泉野小学校6年の担任の前多光子先生が,4月の社会の授業の最初に1時間かけて何のために歴史を学ぶのかということをひたすら子どもたちに問い続けた。みんなで考え続ける時間がとても長かった。で,結論は「温故知新(ふるきをたずねてあたらしきをしる)」ということだった。学校生活で数少ない印象的だった授業の一つである。
さて,学習漫画のほうに話を戻す。
わかったことは,日本の政治は悪者が担ってきたということだ。どおりで最近の政権支持率が40%で高止まりしているわけだ。子どものときからみんながこの37年に渡るベストセラーの学習漫画で育っている。そんなわけで,今の50歳以下の世代は我々と違って政治の本質を見抜いてしまっており,なおかつこれが歴史というものだとあきらめて(達観して)いるのかもしれない。その土壌の上に新自由主義が猖獗するのもしょうがない。
さっそく読み始めました。いやーおもしろくてためになる。高校のときは理数科で世界史と日本史は片方のみが選択だった。それならば世界史でしょうということで,受験に不利かもしれない世界史を選択したため,日本史は小学校の知識でとどまっている。中学校社会の歴史は,途中で交代もあったかもしれないなんだかもうひとつの先生で(地理の米山先生は若くて授業に集中できたのに),試験の成績も全く振るわなかったのだ。
小学校で歴史を学ぶのは6年生である。5年生が地理。その泉野小学校6年の担任の前多光子先生が,4月の社会の授業の最初に1時間かけて何のために歴史を学ぶのかということをひたすら子どもたちに問い続けた。みんなで考え続ける時間がとても長かった。で,結論は「温故知新(ふるきをたずねてあたらしきをしる)」ということだった。学校生活で数少ない印象的だった授業の一つである。
さて,学習漫画のほうに話を戻す。
わかったことは,日本の政治は悪者が担ってきたということだ。どおりで最近の政権支持率が40%で高止まりしているわけだ。子どものときからみんながこの37年に渡るベストセラーの学習漫画で育っている。そんなわけで,今の50歳以下の世代は我々と違って政治の本質を見抜いてしまっており,なおかつこれが歴史というものだとあきらめて(達観して)いるのかもしれない。その土壌の上に新自由主義が猖獗するのもしょうがない。
2020年3月12日木曜日
各国の感染者比(2)
各国の感染者比(1)からの続き
新型コロナウイルス感染症の話。
感染者数が一定の数あるいは人口比になった日時とその値を共通の原点として,各国の感染者数や人口比を対数グラフに表して観察する方法についてSNS上であれこれ話題になっている。最初の指摘は「他国と比べて日本だけが特異な振る舞いを示しているのは人為的な要因(検査の絞り込み等)の結果ではないか」というものであった。
これに対して,感染者数基準のプロットではほとんど重なって見えた他国・地域については,人口比にすれば分離して見えることを指摘した。それにもかかわらず,中国,湖北省(武漢以外),韓国,日本,イタリア,イランの比較では日本だけが異なった傾向を見せた(緩慢な指数関数型増加)。一方,症例の少ない多くの国を含めて比較すれば,日本だけが特異なのではないというクレームがついていた。ただし,無原則にあれもこれも混ぜてしまうのは問題の本質を見失う危険性があるので正しくない方法論だ。
そこで,アジア太平洋地域で一定の感染者が報告されている国々と日本,韓国について前回と同様の分析を行った。対象は,韓国,日本,台湾,香港,シンガポール,オーストラリアの6カ国とした。なお,今回の追加データは,ジョンズ・ホプキンズ大学のアーカイブから取得している。各国の人口,1ppm達成日,3/9時点での新規確定感染数累計(Confirmed)/人口(Population)は,オーストラリア(2460万人,2月29日,3.7ppm),日本(12600万人,2月22日,4.1ppm),韓国(5180万人,2月19日,140ppm),シンガポール(560万人,1月27日,15ppm),台湾(2360万人,2月20日,1.9ppm),香港(740万人,1月26日,8.1ppm)である。

新型コロナウイルス感染症の話。
感染者数が一定の数あるいは人口比になった日時とその値を共通の原点として,各国の感染者数や人口比を対数グラフに表して観察する方法についてSNS上であれこれ話題になっている。最初の指摘は「他国と比べて日本だけが特異な振る舞いを示しているのは人為的な要因(検査の絞り込み等)の結果ではないか」というものであった。
これに対して,感染者数基準のプロットではほとんど重なって見えた他国・地域については,人口比にすれば分離して見えることを指摘した。それにもかかわらず,中国,湖北省(武漢以外),韓国,日本,イタリア,イランの比較では日本だけが異なった傾向を見せた(緩慢な指数関数型増加)。一方,症例の少ない多くの国を含めて比較すれば,日本だけが特異なのではないというクレームがついていた。ただし,無原則にあれもこれも混ぜてしまうのは問題の本質を見失う危険性があるので正しくない方法論だ。
そこで,アジア太平洋地域で一定の感染者が報告されている国々と日本,韓国について前回と同様の分析を行った。対象は,韓国,日本,台湾,香港,シンガポール,オーストラリアの6カ国とした。なお,今回の追加データは,ジョンズ・ホプキンズ大学のアーカイブから取得している。各国の人口,1ppm達成日,3/9時点での新規確定感染数累計(Confirmed)/人口(Population)は,オーストラリア(2460万人,2月29日,3.7ppm),日本(12600万人,2月22日,4.1ppm),韓国(5180万人,2月19日,140ppm),シンガポール(560万人,1月27日,15ppm),台湾(2360万人,2月20日,1.9ppm),香港(740万人,1月26日,8.1ppm)である。

図 各国の感染者比(基準日は1ppm時点,縦軸はppmの常用対数)
(1)韓国と台湾は,それぞれ異なった水準ではあるが収束に向かう様子が窺える。
(2)欧州の感染者急増国の多くは韓国と相似形の振る舞いをしている。
(3)取り上げたアジア太平洋諸国(韓国,台湾以外,日本を含む)は対数グラフでおおよそなだらかな1次関数で増加している(すなわち,底の小さな指数関数的増加)。したがって,まだ収束の様子はみられない。
(4)香港とシンガポールは1次関数のスロープが原点から2週目以降でよりゆるやかに変化している。なんらかの抑制策が効果を発揮したのかもしれない。シンガポールは0日から18日まで平均15.5%,18日から42日まで平均3.5%で増加,香港は0日から15日まで平均11.0%,15日から43日まで平均4%で増加している。なお,日本は,0日から16日まで平均9%とその中間になっている。
2020年3月11日水曜日
ワン・モア・ヌーク:藤井太洋(2)
3月14日のエピローグも含めて,3月10日で丁度ワン・モア・ヌークを読了した。たいへん知的でスリリングで映画にしたらおもしろいなあと思いながらスイスイと読み進むことができた。テーマとしては9年目を迎える東日本大震災に伴う福島第一原子力発電所事故にピタリと照準をあわせてきた。原子爆弾に関するディテールとこれにイスラム国のテロがうまく調和した内容になっている。もちろん本当の専門家から見ればなんだこれはということになるのだろうけれど,我々素人からすれば十分にリアルに感じられる。
残念ながら著者の福島原発被害者の不安に寄り添おうとする視点には共感できなかった。これはほとんど例のアンチニセ科学グループの思想と同じだったから。具体的には65ページの「テレビ,新聞,雑誌やインターネットを通して死の恐怖を感じさせる言葉をひっきりなしに浴びせられた中で・・・」から67ページの「実はこの程度の被爆でがんの発症例が増えたという疫学的な証拠はない」あたりまで。著者の説明はほとんど間違ってはいないかもしれないが,同時に警鐘をならす人々をすべて飲み込んでしまう効果をもたらしている。そして今も処理水という名のトリチウム+未処理放射性物質の海洋投棄や小児甲状腺がんの診断をめぐってその闘いは続いている。キクマコよりおしどりマコが,早野龍五より牧野淳一郎が信頼できる。
ワン・モア・ヌークはおもしろかったのでこれは評価したい。ただ,こころに残るかというとどうだろうか。この程度の科学的な精度を持ちながらより深い思索をもたらすものを読んでみたい。安部公房は残念ながらもういない。
残念ながら著者の福島原発被害者の不安に寄り添おうとする視点には共感できなかった。これはほとんど例のアンチニセ科学グループの思想と同じだったから。具体的には65ページの「テレビ,新聞,雑誌やインターネットを通して死の恐怖を感じさせる言葉をひっきりなしに浴びせられた中で・・・」から67ページの「実はこの程度の被爆でがんの発症例が増えたという疫学的な証拠はない」あたりまで。著者の説明はほとんど間違ってはいないかもしれないが,同時に警鐘をならす人々をすべて飲み込んでしまう効果をもたらしている。そして今も処理水という名のトリチウム+未処理放射性物質の海洋投棄や小児甲状腺がんの診断をめぐってその闘いは続いている。キクマコよりおしどりマコが,早野龍五より牧野淳一郎が信頼できる。
ワン・モア・ヌークはおもしろかったのでこれは評価したい。ただ,こころに残るかというとどうだろうか。この程度の科学的な精度を持ちながらより深い思索をもたらすものを読んでみたい。安部公房は残念ながらもういない。
2020年3月10日火曜日
各国の感染者比(1)
各国の新規確定感染者数の累計(Confirmed)が100名または200名となった時点を1としてその前後の感染者数累計を対数プロットしたものがtwitter上でいくつか紹介され,日本だけが異なった振る舞いを示していることが指摘されている。日本の感染者数の統計が不自然ではないかということはこれまでも話題になってきた。
ところで国によって人口は大きく異なるのにもかかわらず基準を100名などの固定した人数にするのはどうかと思う。そこで,新規確定感染者数の累計(Confirmed)を各国/地域の人口で割った感染者比が1ppm(百万分の一)となるところを基準にしてそれらの時間経過を比較してみよう。データはWHOのCoronavirus disease (COVID-2019) situation reportsを用いる。感染者数が多い次の6つの国や地域(日本を含む),(1) 中国(13億9500万人)(2) 湖北省(武漢以外)(4800万人),(3) 韓国(5200万人),(4) 日本(1億2700万人),(5) イタリア(6000万人),(6) イラン(8100万人)を選んだ。
それぞれの国の現在(グラフの終端 3/9/2020)の感染者比と感染者が1ppmになる日時はおおむね次のようになっている。(1) 中国(58ppm,1月25日),(2) 湖北省(武漢以外)(370ppm,1月21日*),(3) 韓国(140ppm,2月19日),(4) 日本(3.8ppm,2月23日),(5) イタリア(120ppm,2月27日),(6) イラン(81ppm,2月25日)その結果は次の図で示される。

(1)各国の1ppm以下のデータはバラつきが大きく,感染症の数理シミュレーションの基礎データとして用いるには不適当である。今後,さらに各国の比較を行う場合は感染者比1ppm以上のデータで議論することが望ましい。
(2)感染者数が多い国おける1ppm以上の感染者比の増加カーブの様子はこれまでのところよく似ている。韓国では中国と同様の飽和が始まっているようだ。韓国,イタリア,イランは現在まで湖北省と中国全土に挟まれたデータ領域で推移している。
(3)感染源近傍の湖北省(武漢以外)に比べ中国全土の感染者比の飽和値は約1/6となっている。中国における湖北省の封じ込めが成功しているのだと考えられる。各国や地域の社会構造(政治・経済・文化)や感染対策効果に依存して感染者比の飽和値が定まっていく。
(4)この中では日本のデータだけが他の国や地域と異なった振る舞いをしている。しかしまだ飽和に達している様子は見られない。なお,1ppmに達していない国のデータを混ぜて議論するべきではない。人口密度の低いオーストラリアなども日本と同様の傾向ではないかとの指摘があり,引き続き原因の分析が必要である。
(注1)日本のデータはWHOのデータの扱いと同様で,ダイヤモンド・プリンセス号の部分は除かれている。
(注2)湖北省(武漢以外)はWHOのデータからは直接得られないので,湖北省(武漢以外)のデータによる考察とモデル計算に基づいている。
(注3)WHOの日本のデータ2月5日分には奥村晴彦さんのCOVID-19が指摘するような誤記があるので修正した。なお,中国のデータも奥村さんのcsvファイルを利用させていただいた。
(注4)中国全土のデータの2月17日の段差は集計方法の変更によるものである。
(注5)*1/30 -> 1/21 に訂正(グラフにはまだ反映されていない 3/15/2020)
[1]感染症の数理シミュレーション(6)
各国の感染者比(2)に続く
ところで国によって人口は大きく異なるのにもかかわらず基準を100名などの固定した人数にするのはどうかと思う。そこで,新規確定感染者数の累計(Confirmed)を各国/地域の人口で割った感染者比が1ppm(百万分の一)となるところを基準にしてそれらの時間経過を比較してみよう。データはWHOのCoronavirus disease (COVID-2019) situation reportsを用いる。感染者数が多い次の6つの国や地域(日本を含む),(1) 中国(13億9500万人)(2) 湖北省(武漢以外)(4800万人),(3) 韓国(5200万人),(4) 日本(1億2700万人),(5) イタリア(6000万人),(6) イラン(8100万人)を選んだ。
それぞれの国の現在(グラフの終端 3/9/2020)の感染者比と感染者が1ppmになる日時はおおむね次のようになっている。(1) 中国(58ppm,1月25日),(2) 湖北省(武漢以外)(370ppm,1月21日*),(3) 韓国(140ppm,2月19日),(4) 日本(3.8ppm,2月23日),(5) イタリア(120ppm,2月27日),(6) イラン(81ppm,2月25日)その結果は次の図で示される。
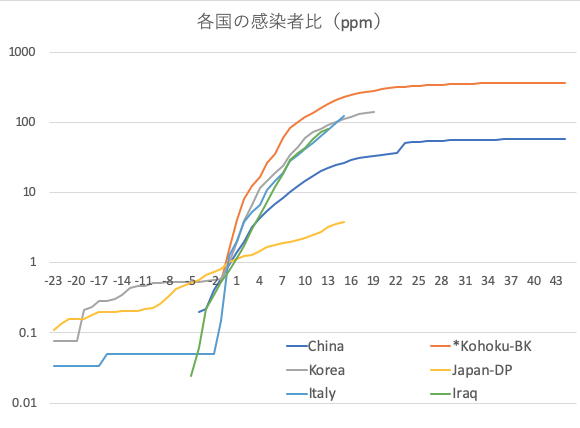
図 各国の感染者比(基準日は1ppm時点,縦軸はppmの常用対数)
(1)各国の1ppm以下のデータはバラつきが大きく,感染症の数理シミュレーションの基礎データとして用いるには不適当である。今後,さらに各国の比較を行う場合は感染者比1ppm以上のデータで議論することが望ましい。
(3)感染源近傍の湖北省(武漢以外)に比べ中国全土の感染者比の飽和値は約1/6となっている。中国における湖北省の封じ込めが成功しているのだと考えられる。各国や地域の社会構造(政治・経済・文化)や感染対策効果に依存して感染者比の飽和値が定まっていく。
(4)この中では日本のデータだけが他の国や地域と異なった振る舞いをしている。しかしまだ飽和に達している様子は見られない。なお,1ppmに達していない国のデータを混ぜて議論するべきではない。人口密度の低いオーストラリアなども日本と同様の傾向ではないかとの指摘があり,引き続き原因の分析が必要である。
(注1)日本のデータはWHOのデータの扱いと同様で,ダイヤモンド・プリンセス号の部分は除かれている。
(注2)湖北省(武漢以外)はWHOのデータからは直接得られないので,湖北省(武漢以外)のデータによる考察とモデル計算に基づいている。
(注3)WHOの日本のデータ2月5日分には奥村晴彦さんのCOVID-19が指摘するような誤記があるので修正した。なお,中国のデータも奥村さんのcsvファイルを利用させていただいた。
(注4)中国全土のデータの2月17日の段差は集計方法の変更によるものである。
(注5)*1/30 -> 1/21 に訂正(グラフにはまだ反映されていない 3/15/2020)
[1]感染症の数理シミュレーション(6)
各国の感染者比(2)に続く
2020年3月9日月曜日
fudan-CCDCモデル
中国の上海にある復旦大学の研究グループが,新型コロナウイルス感染症(COVID-19)の流行を推測するために,統計的な時間遅延力学系モデル(fudan-CCDCモデル)を考案した。CCDC(中国疾病予防センター)は中国の防疫拠点であるがそこで得られたデータを再現している。彼らはこのモデルを用いて [1] の論文を2月21日に報告した。
日本でも,このモデルによる感染予測が始まった [2][3][4]。いずれも厚生労働省のデータをもとにしてパラメタを推定している。KEN_KEN2さんのpythonを使った計算によれば,3/10ごろに確定感染者が2000人となりそうだ。3月のはじめの数日の新規感染者数については厚生労働省の報告値の2倍以上の推計値を与えており,モデルが原因なのかデータが原因なのかはわからない。また,林祐輔さんのpythonを使った計算によれば,政府の観測にかからない潜在感染者数が 3月9日時点で約2万人あり,ピークアウトするのは4月末〜5月初旬という結果を得ている(注:この潜在感染者数は我々のSIIDR2モデルでは$u_2(t)$に対応する)。いずれもソースコードが公開された貴重な資料となっている。
ところで,復旦大学グループの論文[1]の結論部分には次のようなコメント「上海と同じ防疫措置を2/20までに実行すれば潜在感染者数は15万人に押さえられるが,2/29にのびれば45万人になるだろう」がある。彼らは日本の感染者数の初期データとしてダイヤモンド・プリンセス号を含めたものを採用し,武漢とほぼ同じ値で増加していることを冒頭で示している。また,これを用いて複数のシナリオに基づくシミュレーションを行っている。残念ながら,これにはダイヤモンド・プリンセス号という特異事例の感染者数の値,すなわち2月10日に135人(日本国内のみ26人)から2月19日に542人(日本国内のみ73人)を含んでおり,第5節のPossible future scenarios for COVID-19 in Japanのシミュレーション部分はミスリーディングである。
[1]CoVID-19 in Japan: What could happen in the future(Fudan University)
[2]中国の最新論文の方式で日本のコロナウイルスの感染者を予想してみた(KEN_KEN2)
[3] Fudan_CCDC_Japan_Optuna.ipynb(林祐輔)
[4]COVID-19 in Japan(林祐輔)
[4]Coronavirus disease (COVID-2019) situation reports(WHO)
日本でも,このモデルによる感染予測が始まった [2][3][4]。いずれも厚生労働省のデータをもとにしてパラメタを推定している。KEN_KEN2さんのpythonを使った計算によれば,3/10ごろに確定感染者が2000人となりそうだ。3月のはじめの数日の新規感染者数については厚生労働省の報告値の2倍以上の推計値を与えており,モデルが原因なのかデータが原因なのかはわからない。また,林祐輔さんのpythonを使った計算によれば,政府の観測にかからない潜在感染者数が 3月9日時点で約2万人あり,ピークアウトするのは4月末〜5月初旬という結果を得ている(注:この潜在感染者数は我々のSIIDR2モデルでは$u_2(t)$に対応する)。いずれもソースコードが公開された貴重な資料となっている。
ところで,復旦大学グループの論文[1]の結論部分には次のようなコメント「上海と同じ防疫措置を2/20までに実行すれば潜在感染者数は15万人に押さえられるが,2/29にのびれば45万人になるだろう」がある。彼らは日本の感染者数の初期データとしてダイヤモンド・プリンセス号を含めたものを採用し,武漢とほぼ同じ値で増加していることを冒頭で示している。また,これを用いて複数のシナリオに基づくシミュレーションを行っている。残念ながら,これにはダイヤモンド・プリンセス号という特異事例の感染者数の値,すなわち2月10日に135人(日本国内のみ26人)から2月19日に542人(日本国内のみ73人)を含んでおり,第5節のPossible future scenarios for COVID-19 in Japanのシミュレーション部分はミスリーディングである。
[1]CoVID-19 in Japan: What could happen in the future(Fudan University)
[2]中国の最新論文の方式で日本のコロナウイルスの感染者を予想してみた(KEN_KEN2)
[3] Fudan_CCDC_Japan_Optuna.ipynb(林祐輔)
[4]COVID-19 in Japan(林祐輔)
[4]Coronavirus disease (COVID-2019) situation reports(WHO)
2020年3月8日日曜日
感染症の数理シミュレーション(6)
感染症の数理ミュレーション(5)からの続き
湖北省(武漢以外)のデータでは,新規/累計感染者数 f(t), g(t) と新規/累計死亡数 h(t), i(t) を簡単な近似関数で表現した。これを用いると,感染症の数理シミュレーション(3)のSIIDR2モデルにおけるパラメータを絞り込むことができるのではないだろうか。
そこで,前回示したSIIDR2の方程式系と今回の実測データ近似関数の関係を整理してみよう。
\begin{equation}
\begin{aligned}
S: \dfrac{du_1}{dt} &= -\dfrac{\beta}{n} u_1 u_2 = -\dfrac{\beta}{n}\alpha_2 f u_1 \\
I_1: \dfrac{du_2}{dt} &= \dfrac{\beta}{n} u_1 u_2 -\dfrac{u_2}{\alpha_1} -\dfrac{u_2}{\alpha_2} = \dfrac{\beta}{n}\alpha_2 f u_1 - (1 + \dfrac{\alpha_2}{\alpha_1}) f \\
I_2: \dfrac{du_3}{dt} &= \dfrac{u_2}{\alpha_2} - \dfrac{u_3}{\gamma_1} -\dfrac{u_3}{\gamma_2} = f - (1 + \dfrac{\gamma_2}{\gamma_1}) h \\
D: \dfrac{du_4}{dt} &= \dfrac{u_3}{\gamma_2} = h\\
R: \dfrac{du_5}{dt} &= \dfrac{u_2}{\alpha_1} + \dfrac{u_3}{\gamma_1} = \dfrac{\alpha_2}{\alpha_1} f + \dfrac{\gamma_2}{\gamma_1} h\\
I_a: \dfrac{du_6}{dt} &= \dfrac{u_2}{\alpha_2} = f
\end{aligned}
\end{equation}
これから次の関係式が得られる。
\begin{equation}
\begin{aligned}
u_1 &= n - u_2 - u_3 - u_4 - u_5\\
u_2 &= \alpha_2 f\\
u_3 &= \gamma_2 h\\
u_4 &= \int h dt = i\\
u_5 &= \dfrac{\alpha_2}{\alpha_1} g + \dfrac{\gamma_2}{\gamma_1}i \\
u_6 &= \int f dt = g
\end{aligned}
\end{equation}
さらに,次の前提条件が成り立つとする。
①感染者の2割が発症する[1]。
②致命率(発症者の死亡率)は0.7%である[2]。
③発症までの平均潜伏期間は$\alpha=5$とする$(1/\alpha=1/\alpha_1+1/\alpha_2)$ [3]。
④基本再生産数$R_o$=2.2(1.4〜3.9)より,$\beta=R_o/\lambda=0.46\pm0.12$ である [2]。
⑤湖北省(武漢以外)の新規死亡数h(t)は20日のピークに0.006/日,40日目の累計で0.12人(1万人当り)[4]。
⑥同上の新規感染者数f(t)は12日のピークに0.25/日,40日目の累計で3.70人(1万人当り)[4]。
$I_2$の$u_3$に対する微分方程式$du_3/dt + u_3/\gamma = f$を解いて求めた$u_3$の関数形が$\gamma_2 h$に近づくように定めると,$\gamma=5,\ \gamma_1=5/0.965, \gamma_2=5/0.035$が得られる。ただし,$(1/\gamma=1/\gamma_1+1/\gamma_2)$である(訂正有り 3/13/2020)→感染症の数理シミュレーション(7)へ
各関数のT日目の値がわかれば,非感染者の減少分$\Delta u_1$は次式で与えられる。
\begin{equation}
\Delta u_1=n-u_1(T)=u_2(t)+u_3(T)+u_4(T)+u_5(T)
\end{equation}
さらに湖北省(武漢以外)のT=40日のデータを代入して,$u_2(T)=\alpha_2 f(T)≒0$, $u_3(T)=\gamma_2 h(T)≒0$より,$\Delta u_1= \dfrac{\alpha_2}{\alpha_1} g(T) + \dfrac{\gamma_2}{\gamma_1}i(T)+i(T) =14.8+3.4=18.2 $である。ここで,$\alpha_1=5/0.8, \alpha_2=5/0.2$という①の仮定を用いた。
$u_1(t)$において,$\beta$が定数であると仮定して微分方程式を解けば,$u_1(t)=n \exp (-\frac{\beta}{n} \alpha_2 g(t))$となることから,$\beta$と$\alpha_2$を与えれば,$u_1(T)=9982$が得られる。先ほどの式と組み合わせると$\beta=0.2$となる。
まとめると,湖北省(武漢以外)のデータを再現するSIIDR2モデルのパラメタのセットは次のようになる。(訂正有り 3/13/2020)→感染症の数理シミュレーション(7)へ
\begin{equation}
\alpha_1=\dfrac{5}{0.8},\ \alpha_2=\dfrac{5}{0.2},\ \beta=0.2,\ \gamma_1=\dfrac{5}{0.965},\ \gamma_2=\dfrac{5}{0.035}
\end{equation}
SIIDR2モデルでは,感染率を時間の関数$\beta(t)$として感染対策が行われることを表している。上記の$\beta$はそれを平均したものと考えることができる。ところで,上記の$I_2$の$u_2$に対する微分方程式は,$du_2/dt + u_2/\alpha = \beta u_2$と近似できる($\therefore u_1/n ≒ 1$)ことから,次のように与えられる。
\begin{equation}
\beta(t) = \dfrac{du_2/dt}{u_2} + \dfrac{1}{\alpha}
\end{equation}
$u_2(t)=\alpha_2 f(t)$を上式に代入したものと,感染症の数理シミュレーション(5)で考えたモデル感染対策時間因子で$\beta=0.91, \lambda=7, \tau=7$と置いたものを下記の図に示す。

図:湖北省(武漢以外)のデータからSIIDR2で導いたβ(t)(下)とモデル化したβ(t)(上)
また,このモデル化された感染対策時間因子$\beta(t)$をt=0からt=40まで積分したものを40日で割って平均すると($T=40, \beta=0.91, \lambda=7, \tau=7$),
\begin{equation}
\bar{\beta} = \dfrac{1}{T} \int_0^T \dfrac{\beta}{15} (8 + 7 \tanh (-(t-\tau)/\lambda ) dt = 0.24
\end{equation}
となって,先ほど湖北省(武漢以外)のデータからSIIDR2モデルを経由して導いた$\beta=0.2$と矛盾しないような感染対策時間因子のパラメタセットが存在することがわかる。
[1]新型コロナウイルス感染症対策の見解(厚生労働省)
[2]新型コロナウイルス(COVID-19)感染症(川名・三笠・泉川)
[3]新型コロナウイルス肺炎COVID-19(下畑享良)
[4]tenetニュースサイト
[5]Coronavirus disease (COVID-2019) situation reports(WHO)
[6]COVID-19(奥村晴彦)
感染症の数理シミュレーション(7)へ続く
湖北省(武漢以外)のデータでは,新規/累計感染者数 f(t), g(t) と新規/累計死亡数 h(t), i(t) を簡単な近似関数で表現した。これを用いると,感染症の数理シミュレーション(3)のSIIDR2モデルにおけるパラメータを絞り込むことができるのではないだろうか。
そこで,前回示したSIIDR2の方程式系と今回の実測データ近似関数の関係を整理してみよう。
\begin{equation}
\begin{aligned}
S: \dfrac{du_1}{dt} &= -\dfrac{\beta}{n} u_1 u_2 = -\dfrac{\beta}{n}\alpha_2 f u_1 \\
I_1: \dfrac{du_2}{dt} &= \dfrac{\beta}{n} u_1 u_2 -\dfrac{u_2}{\alpha_1} -\dfrac{u_2}{\alpha_2} = \dfrac{\beta}{n}\alpha_2 f u_1 - (1 + \dfrac{\alpha_2}{\alpha_1}) f \\
I_2: \dfrac{du_3}{dt} &= \dfrac{u_2}{\alpha_2} - \dfrac{u_3}{\gamma_1} -\dfrac{u_3}{\gamma_2} = f - (1 + \dfrac{\gamma_2}{\gamma_1}) h \\
D: \dfrac{du_4}{dt} &= \dfrac{u_3}{\gamma_2} = h\\
R: \dfrac{du_5}{dt} &= \dfrac{u_2}{\alpha_1} + \dfrac{u_3}{\gamma_1} = \dfrac{\alpha_2}{\alpha_1} f + \dfrac{\gamma_2}{\gamma_1} h\\
I_a: \dfrac{du_6}{dt} &= \dfrac{u_2}{\alpha_2} = f
\end{aligned}
\end{equation}
これから次の関係式が得られる。
\begin{equation}
\begin{aligned}
u_1 &= n - u_2 - u_3 - u_4 - u_5\\
u_2 &= \alpha_2 f\\
u_3 &= \gamma_2 h\\
u_4 &= \int h dt = i\\
u_5 &= \dfrac{\alpha_2}{\alpha_1} g + \dfrac{\gamma_2}{\gamma_1}i \\
u_6 &= \int f dt = g
\end{aligned}
\end{equation}
さらに,次の前提条件が成り立つとする。
①感染者の2割が発症する[1]。
②致命率(発症者の死亡率)は0.7%である[2]。
③発症までの平均潜伏期間は$\alpha=5$とする$(1/\alpha=1/\alpha_1+1/\alpha_2)$ [3]。
④基本再生産数$R_o$=2.2(1.4〜3.9)より,$\beta=R_o/\lambda=0.46\pm0.12$ である [2]。
⑤湖北省(武漢以外)の新規死亡数h(t)は20日のピークに0.006/日,40日目の累計で0.12人(1万人当り)[4]。
⑥同上の新規感染者数f(t)は12日のピークに0.25/日,40日目の累計で3.70人(1万人当り)[4]。
$I_2$の$u_3$に対する微分方程式$du_3/dt + u_3/\gamma = f$を解いて求めた$u_3$の関数形が$\gamma_2 h$に近づくように定めると,$\gamma=5,\ \gamma_1=5/0.965, \gamma_2=5/0.035$が得られる。ただし,$(1/\gamma=1/\gamma_1+1/\gamma_2)$である(訂正有り 3/13/2020)→感染症の数理シミュレーション(7)へ
各関数のT日目の値がわかれば,非感染者の減少分$\Delta u_1$は次式で与えられる。
\begin{equation}
\Delta u_1=n-u_1(T)=u_2(t)+u_3(T)+u_4(T)+u_5(T)
\end{equation}
さらに湖北省(武漢以外)のT=40日のデータを代入して,$u_2(T)=\alpha_2 f(T)≒0$, $u_3(T)=\gamma_2 h(T)≒0$より,$\Delta u_1= \dfrac{\alpha_2}{\alpha_1} g(T) + \dfrac{\gamma_2}{\gamma_1}i(T)+i(T) =14.8+3.4=18.2 $である。ここで,$\alpha_1=5/0.8, \alpha_2=5/0.2$という①の仮定を用いた。
$u_1(t)$において,$\beta$が定数であると仮定して微分方程式を解けば,$u_1(t)=n \exp (-\frac{\beta}{n} \alpha_2 g(t))$となることから,$\beta$と$\alpha_2$を与えれば,$u_1(T)=9982$が得られる。先ほどの式と組み合わせると$\beta=0.2$となる。
まとめると,湖北省(武漢以外)のデータを再現するSIIDR2モデルのパラメタのセットは次のようになる。(訂正有り 3/13/2020)→感染症の数理シミュレーション(7)へ
\begin{equation}
\alpha_1=\dfrac{5}{0.8},\ \alpha_2=\dfrac{5}{0.2},\ \beta=0.2,\ \gamma_1=\dfrac{5}{0.965},\ \gamma_2=\dfrac{5}{0.035}
\end{equation}
SIIDR2モデルでは,感染率を時間の関数$\beta(t)$として感染対策が行われることを表している。上記の$\beta$はそれを平均したものと考えることができる。ところで,上記の$I_2$の$u_2$に対する微分方程式は,$du_2/dt + u_2/\alpha = \beta u_2$と近似できる($\therefore u_1/n ≒ 1$)ことから,次のように与えられる。
\begin{equation}
\beta(t) = \dfrac{du_2/dt}{u_2} + \dfrac{1}{\alpha}
\end{equation}
$u_2(t)=\alpha_2 f(t)$を上式に代入したものと,感染症の数理シミュレーション(5)で考えたモデル感染対策時間因子で$\beta=0.91, \lambda=7, \tau=7$と置いたものを下記の図に示す。

図:湖北省(武漢以外)のデータからSIIDR2で導いたβ(t)(下)とモデル化したβ(t)(上)
また,このモデル化された感染対策時間因子$\beta(t)$をt=0からt=40まで積分したものを40日で割って平均すると($T=40, \beta=0.91, \lambda=7, \tau=7$),
\begin{equation}
\bar{\beta} = \dfrac{1}{T} \int_0^T \dfrac{\beta}{15} (8 + 7 \tanh (-(t-\tau)/\lambda ) dt = 0.24
\end{equation}
となって,先ほど湖北省(武漢以外)のデータからSIIDR2モデルを経由して導いた$\beta=0.2$と矛盾しないような感染対策時間因子のパラメタセットが存在することがわかる。
[1]新型コロナウイルス感染症対策の見解(厚生労働省)
[2]新型コロナウイルス(COVID-19)感染症(川名・三笠・泉川)
[3]新型コロナウイルス肺炎COVID-19(下畑享良)
[4]tenetニュースサイト
[5]Coronavirus disease (COVID-2019) situation reports(WHO)
[6]COVID-19(奥村晴彦)
感染症の数理シミュレーション(7)へ続く
2020年3月7日土曜日
感染症の数理シミュレーション(5)
感染症の数理シミュレーション(4)からの続き
ここ1,2週間が瀬戸際といわれ続けて,2週間を迎えようとしている。そこで,対策の効果や時期を感染率$\beta(t)$という1つの時間依存のパラメタに代表させ,これが感染者の増加にどのような影響を及ぼすかを見えるようにしたい。
感染症の数理シミュレーション(3)では,SIIDR2モデルとして,感染対策によって感染率を下げる効果を,感染シミュレーション開始時を基点とする指数関数的な因子$\beta(t) = \beta \exp(-t/\lambda) $によって導入した。これは,感染対策時間$\lambda$の数倍で感染率をほとんどゼロに近づけてしまうが,それは難しいのではないだろうか。
そこで,感染率を1桁程度減少させるとともに,対策導入日$\tau$を新たなパラメータとして加えた新しい対策時間因子を含む感染率を定義する。
\begin{equation}
\beta(t) =\dfrac{\beta}{15} \{ 8 + 7 \tanh \dfrac{-(t - τ)}{\lambda} \}
\end{equation}
感染対策の前後にはそれぞれ$\beta$及び$\beta/15$という一定の感染率を与える(15にはとくに根拠はない,パラメータの定量的な精度は求めておらず,オーダやファクターの評価ができればよいという立場である)。もし,対策開始日が$\tau=0$であれば,シミュレーション開始日の$t=0$の$\beta(0)=8\beta/15$となるので,これまでの$\beta$の定義の半分の値になっていることに注意する。
$\beta(t)$を$\beta$で割って,感染対策時間因子だけを取り出したものをグラフにすると次のようになる。横軸はシミュレーション開始からの日数を表す。


ここ1,2週間が瀬戸際といわれ続けて,2週間を迎えようとしている。そこで,対策の効果や時期を感染率$\beta(t)$という1つの時間依存のパラメタに代表させ,これが感染者の増加にどのような影響を及ぼすかを見えるようにしたい。
感染症の数理シミュレーション(3)では,SIIDR2モデルとして,感染対策によって感染率を下げる効果を,感染シミュレーション開始時を基点とする指数関数的な因子$\beta(t) = \beta \exp(-t/\lambda) $によって導入した。これは,感染対策時間$\lambda$の数倍で感染率をほとんどゼロに近づけてしまうが,それは難しいのではないだろうか。
そこで,感染率を1桁程度減少させるとともに,対策導入日$\tau$を新たなパラメータとして加えた新しい対策時間因子を含む感染率を定義する。
\begin{equation}
\beta(t) =\dfrac{\beta}{15} \{ 8 + 7 \tanh \dfrac{-(t - τ)}{\lambda} \}
\end{equation}
感染対策の前後にはそれぞれ$\beta$及び$\beta/15$という一定の感染率を与える(15にはとくに根拠はない,パラメータの定量的な精度は求めておらず,オーダやファクターの評価ができればよいという立場である)。もし,対策開始日が$\tau=0$であれば,シミュレーション開始日の$t=0$の$\beta(0)=8\beta/15$となるので,これまでの$\beta$の定義の半分の値になっていることに注意する。
$\beta(t)$を$\beta$で割って,感染対策時間因子だけを取り出したものをグラフにすると次のようになる。横軸はシミュレーション開始からの日数を表す。

図1 感染対策時間因子β(t) λ=5 左からτ=5,10,15

図2 感染対策時間因子β(t) τ=20 急峻な方からλ=5,10,15
どうやら政府は情報公開に力を入れるのではなく,マスコミやインターネットにおける情報抑制に全力を投球し始めた。ますます,正確な情報が見えなくなってしまう。
2020年3月6日金曜日
ワン・モア・ヌーク:藤井太洋(1)
2020年3月5日木曜日
湖北省(武漢以外)のデータ
新型コロナウイルス感染症の事例数が最も多い地位は中国の湖北省であるが,武漢のデータは特異的な値を示している(高い死亡率)。そこで,モデルの妥当性を検討するためには湖北省(武漢以外)のデータを用いるのが適当だ。tencentのニュースサイトには湖北省(武漢以外)のデータが報告されている。
湖北省(武漢以外)の新規感染者数データの実測値 K(t) にはバラつきがあるが,次のような傾向を持っている。
・K(t)は40日の範囲で0から増加してその後減衰して0に近づく。
・そのピークはt=14日のK(t)=1200人である。
・この40日間の感染者数の累計数は$\int K(t) dt$ = 17,800人である。
この性質をみたす簡単な近似関数を求めておけば,感染モデルとの比較が容易になる。K(t)の解析的な近似関数をf(t)(一日に報告される新規感染者の数)とし,その積分をg(t)(新規感染者の累計数)とする。
目の子で探すと,tを報告開始からの日数として次のようになる。
$f(t) = 3 t^4 \exp(-t/3)$
f'(12)=0, f(12)=1140, g(40)=17400 など,観測データをおおむね再現している。
感染症の数理シミュレーション(3)で用いたSIIDR2モデルでは,$u_6$がg(t)に対応する。なお,$u_6(t)$は重症感染者数$u_3(t)$の変化分から減少項を除いたものを積分したものである。

図1 湖北省(武漢以外)の新規/累計感染者数の近似関数,上がg(t),下がf(t)(横軸は日,縦軸は1万人当たり)
湖北省(武漢以外)での1万人当りの累計感染者数(t=40)は3.7人,新規感染者数(t=peak)は0.25人,死亡数(t=40)は0.12人である。
P. S.
なお,死亡数についても20日をピークとする滑らかな関数となっているので,新規/
累計死亡数の近似関数を求めることができる。それぞれh(t), i(t)とすると,
$h(t) = 30 \sin^2[ \pi / 40 t]$で与えられる。ピーク時の一日あたりの死亡数は30人であり,40日目にはおおむね収束に近づいている。これをグラフにすると次のようになる。
 図2 湖北省(武漢以外)の新規/累計死亡数の近似関数,上がi(t),下がh(t)(横軸は日,縦軸は1万人当たり)
図2 湖北省(武漢以外)の新規/累計死亡数の近似関数,上がi(t),下がh(t)(横軸は日,縦軸は1万人当たり)
湖北省(武漢以外)の新規感染者数データの実測値 K(t) にはバラつきがあるが,次のような傾向を持っている。
・K(t)は40日の範囲で0から増加してその後減衰して0に近づく。
・そのピークはt=14日のK(t)=1200人である。
・この40日間の感染者数の累計数は$\int K(t) dt$ = 17,800人である。
この性質をみたす簡単な近似関数を求めておけば,感染モデルとの比較が容易になる。K(t)の解析的な近似関数をf(t)(一日に報告される新規感染者の数)とし,その積分をg(t)(新規感染者の累計数)とする。
目の子で探すと,tを報告開始からの日数として次のようになる。
$f(t) = 3 t^4 \exp(-t/3)$
f'(12)=0, f(12)=1140, g(40)=17400 など,観測データをおおむね再現している。
感染症の数理シミュレーション(3)で用いたSIIDR2モデルでは,$u_6$がg(t)に対応する。なお,$u_6(t)$は重症感染者数$u_3(t)$の変化分から減少項を除いたものを積分したものである。

図1 湖北省(武漢以外)の新規/累計感染者数の近似関数,上がg(t),下がf(t)(横軸は日,縦軸は1万人当たり)
湖北省(武漢以外)での1万人当りの累計感染者数(t=40)は3.7人,新規感染者数(t=peak)は0.25人,死亡数(t=40)は0.12人である。
P. S.
なお,死亡数についても20日をピークとする滑らかな関数となっているので,新規/
累計死亡数の近似関数を求めることができる。それぞれh(t), i(t)とすると,
$h(t) = 30 \sin^2[ \pi / 40 t]$で与えられる。ピーク時の一日あたりの死亡数は30人であり,40日目にはおおむね収束に近づいている。これをグラフにすると次のようになる。

2020年3月4日水曜日
あぶり餅
京都の紫野今宮神社には名物のあぶり餅屋がある。境内前に2軒ありそのうちの一文字屋和輔,一和のほうに入った。新型コロナウイルス感染症の影響で,京都は観光客が少なく,あぶり餅屋も手持ちぶさた。庭のみえるお座敷に通されたが,我々夫婦の他には誰もいない。名物のあぶり餅はおいしかった。その縁起によれば,一条天皇(980-1011)の頃に悪疫がはやり,今宮神社で悪疫退散の祈願をした。そのときに初代が,この阿ぶり餅を神前に供え,そのお下がりを喰う人が疫病をのがれたとのこと。一和の創業は長保二年(1000)とある,すごすぎる。というわけで,疫病退散の今宮神社と一和を訪れたのはまことにタイムリーだったわけである。
疫病対策に大仏を建立したり,祇園祭を始めたり,あぶり餅を普及させたりと,奈良や京都では昔から工夫をこらし,その成果が観光資源として現在まで続いている。疫病の社会に対するインパクトはこれほどまでに大きい。このたびの新型コロナ疫でも後世に残るような文化資産につながる対策を考案する必要があるのではないかいな。


写真:あぶり餅の一和(2020年3月3日撮影)
疫病対策に大仏を建立したり,祇園祭を始めたり,あぶり餅を普及させたりと,奈良や京都では昔から工夫をこらし,その成果が観光資源として現在まで続いている。疫病の社会に対するインパクトはこれほどまでに大きい。このたびの新型コロナ疫でも後世に残るような文化資産につながる対策を考案する必要があるのではないかいな。


写真:あぶり餅の一和(2020年3月3日撮影)
2020年3月3日火曜日
休校中の高校生に贈る「情報」の課題A
[課題A]
新型コロナウイルス感染症の拡大を防ぐためという理由で,3月2日から全国ほぼ一斉に小中高等学校が休校となりました。これが本当に効果があるのかどうかを検討し,より良い対策がないかをグループで相談しながら考えてください。なお,国会中継がある日は必ずそれを見るようにしてください。
①日本における人々全体の平均的な1日における感染機会C(活動)は,(1)その活動をする人数の割合(分母は日本の人口),(2)その活動時間(分母は24時間),(3)その活動中の平均的な人の密集度(単位は人/㎡),の3つの積をすべての人について加えたものに比例すると仮定します。このとき,全国の学校を休校にした効果,すなわちC(平常時)-C(休校時)はいくらになるでしょうか,考えて下さい。
(ヒント)ある人のブログに「全国の小中高等学校の休業の効果」という計算例があるので,どうしてもわからない場合にはこれも参考にして下さい。
②全国の学校を休校にする以外で,社会を大きく混乱させずに感染機会を減らすにはどうすればよいか,それぞれについてC(活動)を計算して,最も効果的な対策を考えなさい。
(ヒント)通勤ラッシュの解消,カラオケ,居酒屋,パチンコ,スポーツジムにいかない,等。ただし,必ず数値的な根拠を引用データによって示してください。
③上記のシミュレーションの前提条件は,どの程度正しいか,どこが間違っている可能性があるのかについて友達と議論してください。
(ヒント)友達がいない場合は家族の方々でも結構です。
新型コロナウイルス感染症の拡大を防ぐためという理由で,3月2日から全国ほぼ一斉に小中高等学校が休校となりました。これが本当に効果があるのかどうかを検討し,より良い対策がないかをグループで相談しながら考えてください。なお,国会中継がある日は必ずそれを見るようにしてください。
①日本における人々全体の平均的な1日における感染機会C(活動)は,(1)その活動をする人数の割合(分母は日本の人口),(2)その活動時間(分母は24時間),(3)その活動中の平均的な人の密集度(単位は人/㎡),の3つの積をすべての人について加えたものに比例すると仮定します。このとき,全国の学校を休校にした効果,すなわちC(平常時)-C(休校時)はいくらになるでしょうか,考えて下さい。
(ヒント)ある人のブログに「全国の小中高等学校の休業の効果」という計算例があるので,どうしてもわからない場合にはこれも参考にして下さい。
②全国の学校を休校にする以外で,社会を大きく混乱させずに感染機会を減らすにはどうすればよいか,それぞれについてC(活動)を計算して,最も効果的な対策を考えなさい。
(ヒント)通勤ラッシュの解消,カラオケ,居酒屋,パチンコ,スポーツジムにいかない,等。ただし,必ず数値的な根拠を引用データによって示してください。
③上記のシミュレーションの前提条件は,どの程度正しいか,どこが間違っている可能性があるのかについて友達と議論してください。
(ヒント)友達がいない場合は家族の方々でも結構です。
2020年3月2日月曜日
全国の小中高等学校の休業の効果
新型コロナウイルス感染症の感染が拡大する中,2月27日(木)の夕方,安倍首相は全国すべての小学校・中学校・高校・特別支援学校等に,3月2日から春休みまでの期間,臨時休業とするよう要請する考えを表明した。そして今日からその休業が始まった。
ここではその是非ではなくて,感染機会を減少させる上で休業の効果がどの程度ありうるかについて考えてみたい。人間の1日の生活時間において感染の機会は,その活動における他人との接触による(間接的なモノを通しての感染もあるとは思う)。このとき,人との距離が近い密集した空間のほうがその危険性は大きいとNHKでも宣伝していた。そこで,1日の活動時間とその活動時の単位面積当りの他者の人数の積和を全国民に渡って平均すれば,感染機会の大きさを定量的に評価できるのではないかと考えた。
まず,生活時間を調べよう。5年おきに実施している最新の平成28年社会生活基本調査のデータをみよう・・・うーん。面倒なので勝手に考えることにする。睡眠7時間,家庭・食事5時間,通勤・通学等1時間,仕事・学校・塾8時間,その他活動3時間。
また,次に平成27年国勢調査と学校基本調査を参考にしよう・・・うーん。まあだいたい,1億2700万人の国民が,幼稚園・幼保連携型認定こども園・保育園に400万人(3%),学校(小〜大)に1700万人(13%),職場に5900万人(47%),老人・乳幼児等が4500万人(35%),病院・介護施設等に200万人(2%)となる。国勢調査によれば世帯数は5300万世帯で,世帯人数が1人(34%),2人(28%),3人(18%),4人(13%),5人以上(7%)となっている。
まず,家庭での時間を考える。15㎡の部屋に家族が集まって食事や団欒の時間を過ごす。その時間が3時間として,睡眠時間を含め9時間は1人でいるものとする。そこで感染機会Cに寄与するのは複数で過ごす時間である。
C(家庭) = 0人/㎡*9時間 + (0*0.34 + 1*0.28 + 2*0.18 + 3*0.13 + 4*0.07)人/15㎡*3時間 = 0.21
次に,学校と職場である。教室の面積を9*7=60㎡として,平均収容人数を30人とすると,
C(幼保+学校) = (0.03 + 0.13)*30人/60㎡*8時間 = 0.64
職場は非常に多様な環境であり,えいやっと1人1坪のオフィスや工場を考える。
C(職場) = 0.47*1人/3.3㎡*8時間 = 1.14
通勤通学時間は,NHKによる2015年の国民生活時間調査と国勢調査が参考になる。徒歩(7%),自転車等(15%),自家用車(47%),電車バス等(31%)である。また,電車の1人当り立席専有面積は0.3㎡らしいので,3.3人/㎡を用いることにする。
C(通勤+通学) =(0.03+0.13+0.47){ (0.07+0.15+0.47)*0人/㎡*1時間 + 0.31*3.3人/㎡*1時間 }= 0.64
その他はよくわからないので,ざっくりと職場と学校の平均0.4人/㎡をとる。
C(その他) = 0.98* 0.4人/㎡ *3時間 = 1.18
病院・介護施設もよくわからないが2%なので家庭に含めてしまった。したがって,
C(全体) = C(家庭) + C(幼保+学校) + C(職場) + C(通勤通学) + C(その他) = 0.21+0.64+1.14+0.64+1.18 = 3.81
学校が休業になるとC(学校)とC(通学)の分は減るが,半分は学童保育などで残るだろう。
なお,小中高等学校だけなので,全人口に対する寄与率は0.13ではなく,高等教育機関などを除いた0.10である。そこで学校一斉休業による減少項は,
C(休校) = {0.10*30/60*8 + 0.10*0.31*3.3 } * 0.5 = 0.25
つまり,この度の全国一斉学校休業による感染機会Cの減少効果は,0.25/3.81≒7%ということになる。まあこんなものだろうか。これからみると,さらに努力することができる部分は家庭や仕事以外のその他の部分である。
P. S. 時差出勤やテレワークなどによって,通勤時の混雑緩和をはかり,乗車率が50%になれば,C(通勤)= {0.47*0.31*3.3 } = 0.24 だけ減少するので,ほぼ全校休校措置と同程度の効果をもたらすことになる。かもしれない。
[1]新型コロナウイルス感染症対策本部(首相官邸)
[2]新型ウイルス研究者試算 対策組み合わせで入院患者6割以上減(NHK)
ここではその是非ではなくて,感染機会を減少させる上で休業の効果がどの程度ありうるかについて考えてみたい。人間の1日の生活時間において感染の機会は,その活動における他人との接触による(間接的なモノを通しての感染もあるとは思う)。このとき,人との距離が近い密集した空間のほうがその危険性は大きいとNHKでも宣伝していた。そこで,1日の活動時間とその活動時の単位面積当りの他者の人数の積和を全国民に渡って平均すれば,感染機会の大きさを定量的に評価できるのではないかと考えた。
まず,生活時間を調べよう。5年おきに実施している最新の平成28年社会生活基本調査のデータをみよう・・・うーん。面倒なので勝手に考えることにする。睡眠7時間,家庭・食事5時間,通勤・通学等1時間,仕事・学校・塾8時間,その他活動3時間。
また,次に平成27年国勢調査と学校基本調査を参考にしよう・・・うーん。まあだいたい,1億2700万人の国民が,幼稚園・幼保連携型認定こども園・保育園に400万人(3%),学校(小〜大)に1700万人(13%),職場に5900万人(47%),老人・乳幼児等が4500万人(35%),病院・介護施設等に200万人(2%)となる。国勢調査によれば世帯数は5300万世帯で,世帯人数が1人(34%),2人(28%),3人(18%),4人(13%),5人以上(7%)となっている。
まず,家庭での時間を考える。15㎡の部屋に家族が集まって食事や団欒の時間を過ごす。その時間が3時間として,睡眠時間を含め9時間は1人でいるものとする。そこで感染機会Cに寄与するのは複数で過ごす時間である。
C(家庭) = 0人/㎡*9時間 + (0*0.34 + 1*0.28 + 2*0.18 + 3*0.13 + 4*0.07)人/15㎡*3時間 = 0.21
次に,学校と職場である。教室の面積を9*7=60㎡として,平均収容人数を30人とすると,
C(幼保+学校) = (0.03 + 0.13)*30人/60㎡*8時間 = 0.64
職場は非常に多様な環境であり,えいやっと1人1坪のオフィスや工場を考える。
C(職場) = 0.47*1人/3.3㎡*8時間 = 1.14
通勤通学時間は,NHKによる2015年の国民生活時間調査と国勢調査が参考になる。徒歩(7%),自転車等(15%),自家用車(47%),電車バス等(31%)である。また,電車の1人当り立席専有面積は0.3㎡らしいので,3.3人/㎡を用いることにする。
C(通勤+通学) =(0.03+0.13+0.47){ (0.07+0.15+0.47)*0人/㎡*1時間 + 0.31*3.3人/㎡*1時間 }= 0.64
その他はよくわからないので,ざっくりと職場と学校の平均0.4人/㎡をとる。
C(その他) = 0.98* 0.4人/㎡ *3時間 = 1.18
病院・介護施設もよくわからないが2%なので家庭に含めてしまった。したがって,
C(全体) = C(家庭) + C(幼保+学校) + C(職場) + C(通勤通学) + C(その他) = 0.21+0.64+1.14+0.64+1.18 = 3.81
学校が休業になるとC(学校)とC(通学)の分は減るが,半分は学童保育などで残るだろう。
なお,小中高等学校だけなので,全人口に対する寄与率は0.13ではなく,高等教育機関などを除いた0.10である。そこで学校一斉休業による減少項は,
C(休校) = {0.10*30/60*8 + 0.10*0.31*3.3 } * 0.5 = 0.25
つまり,この度の全国一斉学校休業による感染機会Cの減少効果は,0.25/3.81≒7%ということになる。まあこんなものだろうか。これからみると,さらに努力することができる部分は家庭や仕事以外のその他の部分である。
P. S. 時差出勤やテレワークなどによって,通勤時の混雑緩和をはかり,乗車率が50%になれば,C(通勤)= {0.47*0.31*3.3 } = 0.24 だけ減少するので,ほぼ全校休校措置と同程度の効果をもたらすことになる。かもしれない。
[1]新型コロナウイルス感染症対策本部(首相官邸)
[2]新型ウイルス研究者試算 対策組み合わせで入院患者6割以上減(NHK)
2020年3月1日日曜日
感染症の数理シミュレーション(4)
感染症の数理シミュレーション(3)からの続き
新型コロナウイルス感染症に対するWHOなどの共同調査報告書[1]が公表された。同時に,新型コロナウイルス感染症の世界的なリスクは4段階のHighからVery Highに引き上げられた。
報告書によれば,感染すると平均で5〜6日後に症状が出る。感染者のおよそ80%は症状が比較的軽く,肺炎の症状がみられない場合もあり,呼吸困難などを伴う重症患者は全体の13.8%,呼吸器の不全や敗血症,多臓器不全など命に関わる重篤な症状の患者は6.1%だとされた。
逆に子どもの感染例は少なく,症状も比較的軽い。19歳以下の感染者は全体の2.4%にとどまり,重症化する人はごくわずかだ。子どもの感染について報告書では主に家庭内で大人から感染しており,子どもから大人への感染例は調査をした中では確認されていないとしている。
ということは,安倍が週末にある世論調査の支持率回復を念頭に慌てて実施した小中高等学校の全国一斉休校要請は十分な根拠がないということだろう。危機的な状況を避けるための適切な判断だという説も多いが,適切な分析やシミュレーションには裏付けられていない(危機感の喚起には一定の意味があるかもしれないが,他がじゃじゃ漏れな状態で一部だけに注力するとよけいな混乱と感染拡大を招きかねない)。
2月20日までのデータによれば,5万5924人の感染者のうち死亡したのは2114人で,全体の致死率は3.8%である。ただし,感染拡大が最も深刻な湖北省武漢だけが致死率が5.8%であり,1月の最初の10日間に発病した患者の致死率は17.3%に達しているので,ここは特異的状況として除いて考えるべきだ。その他の地域の最近の致死率は0.7%である。疫学における致死率(致命率=case fatality rate)とは,特定の疾患に感染した母集団に対する死亡数の割合である。ここで,疾患に感染していることが判明している必要があるので,今回のようにほぼ無症状や他の疾患と区別できない軽症の感染者がいる場合には取り扱いに注意がいる。
感染症の数理シミュレーション(3)では,東大の黒田産業医のデータをもとにパラメタを定めたが,今回のWHO報告とほぼ整合している。ウイルスの伝搬可能な感染者全体のうち症状があって報告に計上される感染者が1/3である(残りの2/3はほぼ無症状や他の疾患と区別できない軽症の感染者)と仮定すれば,上記の13.8%の1/3の4.6%が重症な感染者であり,モデルの$\alpha_2 / \lambda$=5%とほぼ一致する。また,致死率0.7%もウイルスの伝搬可能な感染者全体を分母にすると1/3になるので0.23%であり,$\gamma_2 / \lambda $=5%としたときの,$\alpha_2 /\lambda \cdot \gamma_2 / \lambda $ = 0.25%とほぼ一致する。
前回のSIIDR2のシミュレーションでは,武漢を除く湖北省のデータに近くて日本に妥当するモデルとして,$\beta=0.20, \lambda=100$を例示した。これは,感染者の初期値が1万人に1人という仮定を含んでいた。感染者が急増した武漢を取り巻く湖北省全体では,それぞれの地域に飛び火した数千人の初期感染者から計算を開始することは,一定の合理性があるが,日本に換算すると,全国で1万人の初期感染者を仮定することになって不自然である。
つまり,SIIDR2を用いた日本の現状のモデルシミュレーションには,1万人当りの感染者の初期値$u_2(0)$,感染率の初期値$\beta$,対策による感染率の減少係数$\lambda$の3要素が必要である。いずれにせよ,合理的な判断ができなくて肝腎の検査がシステマティックに行われず,感染状況に関するデータが完全に欠落している日本では推定が難しい。
[1]Report of the WHO-China Joint Mission on Coronavirus Disease 2019 (COVID-19)
新型コロナウイルス感染症に対するWHOなどの共同調査報告書[1]が公表された。同時に,新型コロナウイルス感染症の世界的なリスクは4段階のHighからVery Highに引き上げられた。
報告書によれば,感染すると平均で5〜6日後に症状が出る。感染者のおよそ80%は症状が比較的軽く,肺炎の症状がみられない場合もあり,呼吸困難などを伴う重症患者は全体の13.8%,呼吸器の不全や敗血症,多臓器不全など命に関わる重篤な症状の患者は6.1%だとされた。
逆に子どもの感染例は少なく,症状も比較的軽い。19歳以下の感染者は全体の2.4%にとどまり,重症化する人はごくわずかだ。子どもの感染について報告書では主に家庭内で大人から感染しており,子どもから大人への感染例は調査をした中では確認されていないとしている。
ということは,安倍が週末にある世論調査の支持率回復を念頭に慌てて実施した小中高等学校の全国一斉休校要請は十分な根拠がないということだろう。危機的な状況を避けるための適切な判断だという説も多いが,適切な分析やシミュレーションには裏付けられていない(危機感の喚起には一定の意味があるかもしれないが,他がじゃじゃ漏れな状態で一部だけに注力するとよけいな混乱と感染拡大を招きかねない)。
2月20日までのデータによれば,5万5924人の感染者のうち死亡したのは2114人で,全体の致死率は3.8%である。ただし,感染拡大が最も深刻な湖北省武漢だけが致死率が5.8%であり,1月の最初の10日間に発病した患者の致死率は17.3%に達しているので,ここは特異的状況として除いて考えるべきだ。その他の地域の最近の致死率は0.7%である。疫学における致死率(致命率=case fatality rate)とは,特定の疾患に感染した母集団に対する死亡数の割合である。ここで,疾患に感染していることが判明している必要があるので,今回のようにほぼ無症状や他の疾患と区別できない軽症の感染者がいる場合には取り扱いに注意がいる。
感染症の数理シミュレーション(3)では,東大の黒田産業医のデータをもとにパラメタを定めたが,今回のWHO報告とほぼ整合している。ウイルスの伝搬可能な感染者全体のうち症状があって報告に計上される感染者が1/3である(残りの2/3はほぼ無症状や他の疾患と区別できない軽症の感染者)と仮定すれば,上記の13.8%の1/3の4.6%が重症な感染者であり,モデルの$\alpha_2 / \lambda$=5%とほぼ一致する。また,致死率0.7%もウイルスの伝搬可能な感染者全体を分母にすると1/3になるので0.23%であり,$\gamma_2 / \lambda $=5%としたときの,$\alpha_2 /\lambda \cdot \gamma_2 / \lambda $ = 0.25%とほぼ一致する。
前回のSIIDR2のシミュレーションでは,武漢を除く湖北省のデータに近くて日本に妥当するモデルとして,$\beta=0.20, \lambda=100$を例示した。これは,感染者の初期値が1万人に1人という仮定を含んでいた。感染者が急増した武漢を取り巻く湖北省全体では,それぞれの地域に飛び火した数千人の初期感染者から計算を開始することは,一定の合理性があるが,日本に換算すると,全国で1万人の初期感染者を仮定することになって不自然である。
つまり,SIIDR2を用いた日本の現状のモデルシミュレーションには,1万人当りの感染者の初期値$u_2(0)$,感染率の初期値$\beta$,対策による感染率の減少係数$\lambda$の3要素が必要である。いずれにせよ,合理的な判断ができなくて肝腎の検査がシステマティックに行われず,感染状況に関するデータが完全に欠落している日本では推定が難しい。
[1]Report of the WHO-China Joint Mission on Coronavirus Disease 2019 (COVID-19)
登録:
投稿 (Atom)